

Transitioning from scale to efficiency in AI model training
A conversation with Vishaal Udandarao on AI model performance and how to get the most out of your training data

If you follow AI you might have heard the phrase, “scale is all you need.” The idea that to continue to improve the performance of AI systems, all you need is bigger models and more data. But as AI has continued its rapid advancement the tide is starting to shift on that paradigm. Many of the new AI language and image models released in 2024 have been a fraction of the size of the models we saw in early 2023. But even these smaller models are data hungry.
That’s where today’s guest comes in. In a widely circulated paper from April of this year, Vishaal Udandarao and his coauthors showed that when it comes to AI image models, while more data is better, it takes an exponential increase in data volume to achieve a linear improvement in model performance. With concerns that AI models have already exhausted much of the easily scrapable data from the web Vishaal’s paper has added fuel to the conversation around how AI progress can continue.

As evidence of the paper’s impact on the AI scale conversation, consider the fact that it was the focus of a video on the popular Computerphile YouTube channel with the title, “Has Generative AI already peaked?”
Vishaal is a second-year PhD student at the Max Plank Institute at The University of Tuebingen. He’s also affiliated with the European Laboratory for Learning and Intelligent Systems. Vishaal and I talk in detail about his paper’s results and about what solutions might be available to help continue the progress of AI model development by leveraging existing data more efficiently.
Vishaal Udandarao, welcome to the podcast.
Yeah, thank you. Thank you for the invitation.
Before we dive into the specifics of your paper, why don't you just kind of give us an overview of what your work was about and what you found, and then we can walk through all the details.
Yeah. So, essentially, we were looking at these large scale, pre-trained models called foundation models — so ChatGPT is an example, GPT-4, which processes both text and images, is another example — and we were trying to understand why these models work so well across different contexts.
To do that, we essentially took a bunch of open source models like them and dug into the pre-training datasets. So, essentially, the training datasets that these models used for learning, and tried to see if there was a connection between what was in the training dataset and how these models perform in the real world. So that was essentially the broad picture.
And the question that we were trying to answer was, “Can most of the capabilities of the current models be explained just by looking at the data that they were trained on, or do they have something more?”
My understanding is your work really focused on image models, models that take text in and then output images and models that take images in and output a text description of that image. Were those the two main kinds of models that you looked at in this work?
Yeah, that's almost correct. So the first type was, of course, the text-to-image models, where you take a text prompt and you feed that into a model, and you get an image output.
The second kind is a model is where you feed both the image and the text together and the model essentially comes up with the similarity between the image and the text. So there's no text output in these models.
And what's important for us to know in terms of how these models are trained with the dataset? is there anything in particular that's worth calling out?
So, I'll start off with the second kind of models. These models are called Contrastive Language-Image Models (CLIP), where essentially you feed in images and text together, and the output you get is the similarity. How similar is the image to the text?
The way these models are trained is you take a massive dataset of image-text pairs, which are sourced from the web, and you simply learn to maximize the similarity of the image and the text that occur in pairs, and you minimize the similarity of the images from all other text. So in this way, you just train this model for a bunch of days and you get this final artifact which can give you a similarity when ingesting an image and a text.
So that's the first kind of model, the CLIP style of models.
The second text-to-image models actually use components of the first type. So in the first type, there are two sub-components of this model, which are called an image encoder and a text encoder. The image encoder processes an input image and the text encoder processes a text input.
And the second type of models, which are text-to-image models, essentially use the text encoder component of the clip models to process texts. So you pass in this text to a text encoder that's already trained, and then you feed that in through another set of models which will finally output your image. So that's how the second class of models, text-to-image models, are trained.
And how big are these models in terms of the number of pairs? I know you tested models that were trained on datasets of various sizes. So what's maybe an example of a smaller sized dataset and a larger size dataset we're talking about here?
Yeah, so the smallest scales of data sets where you would sort of see decent performance would be around three to 5 million image-text pairs. So that's the scale we are talking about, which is at the smaller end.
In our paper, we only tested models trained on 400 million image-text pairs, but currently there are models that are trained on up to two or 3 billion image-text pairs. So that's the larger end of the scale.
And is there anything important to say about the data curation and data cleaning, or maybe lack thereof, with these datasets? Because I'm sure listeners know the web is messy.
I had a previous conversation with Stefan Back from Mozilla, who did a big project on the Common Crawl and kind of researching the data that's in there. The Common Crawl tries to do some curation, but they also intentionally keep some “junk” and “messy stuff” and biased material in the dataset, because they want researchers to be able to study bias. So a lot of these datasets are derived from Common Crawl or similar sources, as you mentioned, from the web, and they contain all kinds of stuff.
The 100-billion webpage dataset that powers AI

This week I spoke to Stefan Baack from the Mozilla Foundation about a recent research article he authored on the Common Crawl. The Common Crawl is the name of both a non-profit open-data company founded in 2008 by Gil Elbaz and the name of the associated dataset.
Is there much cleaning and curation of these data sets to remove certain kinds of images or certain kinds of text-image pairs or to look at the description of the image to see if it's coherent English? What does the cleaning process look like? Do we know?
So that's actually a very active and bubbling research area currently, because as you said, the web is quite nasty, right? And all the data sets that we currently use for pre-training, these models are usually sourced from Common Crawl because it's the easiest way to get massive amounts of data. And on top of that you would want to do some sort of filtering.
So I can talk about the datasets that we used and the sort of cleaning that went into curating them. So on the smaller end CC3M and CC12M — which roughly have about 3 million and 12 million image-text pairs, respectively — have a lot of cleaning that went into their creation.
And the key thing to note here is some of these data sets were collected with different objectives, right? So some of these datasets were collected prior to the current boom of CLIP-style model training. Before this, people were looking at how to train good captioning models, for example. So these datasets have been around for a while, and the intent behind these collections is very important.
The reason I say this is because the CC3M dataset, for instance, the cleaning that went into it actually was very, very thorough and removed any kind of nasty content, made sure that the images and the texts were very aligned and exactly match the descriptions. The reason being that this dataset was primarily curated to train captioning models. So you wouldn't want a captioning model to output a bunch of junk, essentially. Even if that meant you sort of filter out a lot of content that might not be useful to filter out.
The second sort of datasets that we have on the upper end are datasets that were primarily collected for training large-scale models. So LAION-400 million and LAION-5 billion are sort of canonical examples of such datasets where you just go into Common Crawl. You dig out all alt-text-image pairs that are in the English language section of Common Crawl, and you apply some filtering operations on them.
But it’s still up for debate as to what are the best sort of filtering mechanisms on top. So there is in fact actually a competition or a leaderboard called DataComp, which essentially is a competition for different kinds of filtering algorithms that you can use.
So the way the competition works is you simply give a filtering algorithm or a filtering mechanism. They will use that to curate data according to that algorithm and retrain a CLIP model and see how performance changes across tasks. So as far as I'm aware this is a very active field of research, and I myself am very curious about different sorts of effects of filtering on the training pipeline.
Is it true that it's generally easier to filter and clean smaller datasets than larger datasets? That seems like it would be intuitively true.
It is true. The reason being currently the state of the art sort of filtering mechanism uses a CLIP model, actually. So it's kind of funny because you're reusing a model to train a model of the same class.
Yeah, that's funny. Okay, let's transition to the kind of key parts of your paper. One thing I wanted to talk about is the notion of zero-shot prompting, because I know your work focuses on this zero-shot notion.
When we think about large language models, as most people use them, we have a few different kind of prompting styles. One is zero-shot, which means you just ask a question or give an instruction without any additional context. We also have a few-shot prompting where we might give some examples of the kind of output we're looking for and then ask the model to use those examples to help its output to us. And we also have chain-of-thought, which is asking the model to think through the steps as it reasons, through a particular problem to produce an output or follow some instructions. Those are all modes of communication and prompting that I'm most familiar with with large language models.
Do we have the same idea of few-shot prompting and chain-of-thought prompting with these kind of image tasks that you studied? Or is it only zero-shot prompting that's available?
So not in the tasks that we study specifically, because the tasks are simple classification or retrieval from a set. However, what you can do is this thing called few-shot fine-tuning. Where it’s the same idea as when you do few-shot prompting? You take a few labeled examples of…for example, if you want to identify a dog, you give a bunch of dog images and say that this is a dog, and you have to fine-tune your model in the sense that it's not the same as prompting, but you have to sort of make the model relearn what these dogs are. And that's the analogy to few-shot prompting. So it's not directly there, but you can get it to work.
But in your work in this paper we're discussing, you only focused on the zero-shot prompting.
Yes. We only focused on zero-shot.
To continue on, you had this, I'll say, concept of a concept. So you developed the idea of a concept, or there's maybe an existing idea of a concept in machine learning. And you had to map this idea of a concept to a dataset and to the images to be able to start creating a baseline of whether the models were able to follow concepts and identify concepts and also measure which concepts occurred most frequently in the various datasets. So what is a concept in the notion that you used it in this paper?
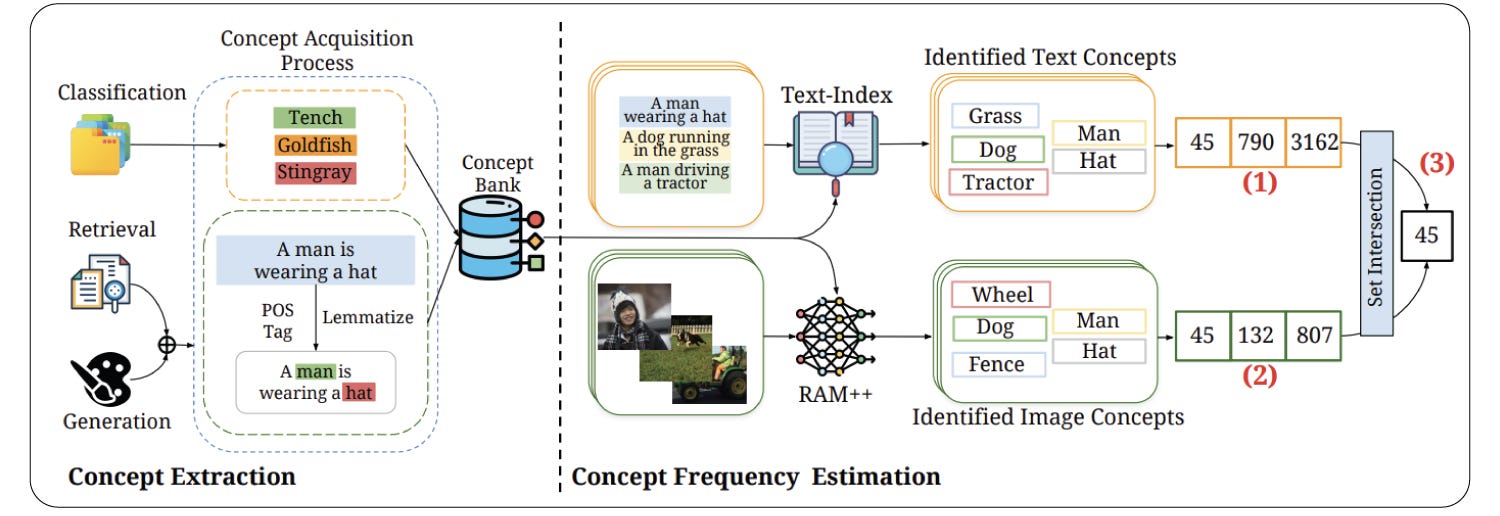
Yeah, that's a very good question because this is something that we were thinking about quite a lot before even doing the work. So, in our work, we define concepts based on the tasks that we are testing.
So we purely test classification, retrieval, and image-generation tasks. So we guide our concept curation based on those tasks. So, for example, in classification, you would be classifying between dogs and cats and maybe cows. So these would be our concepts. We just directly take the sort of names of the classes we want to classify between. For retrieval, you're given a sentence, and you sort of can pick out the nouns from the sentence, and the nouns then make up our concept list.
Similarly, for image generation, you're given a bunch of prompts that you feed into the model to get an image output, and we can use the same noun collection method on the prompt to get the concepts. So in our work, we purely focused on curating concepts conditional on what we are actually testing for.
So there's some kind of reduction in dimensionality, I guess, between the initial data set and these concepts because you might have a dataset that has, I don't know, 100,000 pictures of a cat, but that will map to just one concept, the concept of a cat, I guess, and your data set that you're using or the concept data set.
I guess my question is, how many concepts are in these data sets?
Yeah, that's a question I think it's very hard to answer because these datasets are massive. You got to, again, recollect the scale. The smallest scale of these datasets is about 3 million to 4 million image-text pairs.
So it's very hard to manually inspect and audit what is actually in these data sets. So you've got to either have automated or semi-automated methods to identify what is in the datasets.
And what this means is you're again using a model to sort of try and find what is in these datasets. So, overall, how many concepts are encompassed in the data set? I'm not fully sure I can answer that question well, because. I don't know. But we can try and sort of create a proxy where we know that these things from the tasks we care about exist in the pre-training dataset.
And that's the sort of focus because we can reliably count those concepts in the large scale pre-training dataset rather than trying to figure out what is the concept diversity in the pre-training dataset itself, unconditionally.
Talk more about the process of how you came up with concepts, because I think in your work, you measured something like 4,000 specific concepts, if I'm not mistaken, and tried to understand the correlation between the frequency of those concepts in the pre-training data and how well the output of these models was able to adhere to those concepts.
So, first of all, did I say that correctly?
Yeah. Yeah, that was right.
So where did this initial set of concepts of 4,000 or so that you studied and used for this work, where did that come from? Like, why these concepts, how were the concepts derived?
Why these concepts? It was because essentially we were trying to look at what people care about when they use these models. And what people care about when using these models are usually three kinds of tasks, right? Classification, when you want to distinguish between different animals or different entities or objects. Similarly, retrieval, where given an image, you want to figure out the closest text match in a massive pool to that image. And image generation, where you feed in a prompt and a model has to give you an image out.
Taking this lens of what do people care about? We curated a bunch of downstream datasets. So when I say downstream, I mean what people care about and from each of these data sets, using the concept curation method I described previously, we just collate all of them into one large pool.
So just to reiterate again, for classification tasks, you know, the class name that you're trying to identify. So we just collate all of them for retrieval. We can pick out the nouns from the text, and similarly, for the generation task, we can pick out the nouns from the text prompts.
So we just concatenate all of these together. And that's what we call our concept set.
So did you do that on the full pre-training dataset?
Concepts we don't take from the pre-training dataset. So there's two separate datasets here, right? The first set of datasets is the pre-training datasets, which are used for training models. The second set of datasets are the datasets that you evaluate your model on. And these evaluation datasets are the classification image-generation and retrieval datasets. So the concepts are gotten from the evaluation datasets. There's no concept extraction from the pre-training data set.
Okay, yeah, that makes sense. And the validation datasets are usually smaller than the training datasets.
Exactly. Yeah, yeah, right.
And once we get the concepts from the evaluation data sets, each concept is searched in the pre-training dataset. And the way we do the search is through automated methods, essentially. So we have these 4,000 concepts. We take each concept, search for the particular concept in the text captions of the pre-training dataset. So simply just doing a string search. And in the images, we again use a model that tags each image with a particular set of concepts, and we match if the downstream concepts that we have are present in the image.
So that's our automated pipeline for counting the frequency of concepts in the pre-training datasets, essentially.
And in the pre-training dataset, the frequency of some of these concepts was very large. Even the smallest frequencies, I think were pretty large.
But what do you want to say there in terms of the frequency of these concepts? Like what's a concept that occurs really frequently and less frequently? What are the orders of magnitude we're talking about?
Yeah. So if I take the instance of the smaller sized pre-trained datasets that are like 3 million samples, there, you would have sort of everyday concepts like for example, a dog and a cat much more frequently, right? So you would have them in the order of magnitude of hundreds of thousands. But then you would also have, what are more arcane concepts, like, for example, a particular species of a mushroom or a particular species of some other animal, which is not as well known. And it's only in particular zoos, for example. These will occur way less frequently because again, we have to realize that these datasets are collected from the web, and the web will naturally have much fewer occurrences of certain species and much more occurrences of just common concepts like dog and cat.

And just to make sure I understood correctly, what I saw is the most frequent concepts are around like a million, on the orders of a million, the frequency of that concept. So again, if I think about like cat, there might be a million images of the concept of a cat. And then, like you said, for these very small concepts, I don't know what the frequency is. Maybe it's like only ten or one or two.
Is that roughly correct?
Yeah, that is roughly correct. Of course it scales with a particular dataset. So with the CC3M, it's much harder to see a million images of cats, you would probably see hundreds of thousands. But for the 400 million dataset, it could easily be that you see a million dogs.
And what did you find about the zero-shot performance? This is kind of the crux and really interesting finding of your work. What did you find about the zero-shot performance and how it was correlated with the frequency of concepts in the training data?
So this was essentially the main finding, and why we think this makes the paper interesting is if you look at the correlation between the zero-shot performance on a particular concept and its frequency in the pre-training data set, this correlation was actually log-linear.
What that means is if you want to linearly improve your performance on a particular concept, you have to exponentially increase the number of times you see that concept in the data. So, essentially, this sort of questions the scaling trends that are currently prevalent in machine learning, because this means that for any particular concept, if you want to just get somewhat better performance, you will have to massively get more samples of that particular concept in the pre-training data.
So, just to summarize, let's say we want to look at the performance of having a text-to-image model. Again, I'll stick with a cat. I'll put an image of a cat. If I give it a prompt to make an image of a cat, it can do so pretty easily. And I think people who have played around with these models know that the reason it can do that is because, again, it has in its training dataset a million images of a cat or whatever. So it really learns quite well what a cat is.
But to take your example of maybe a specific kind of mushroom, because there's only, I don't, a handful of examples of this specific type of mushroom. If we try to get the model to output a image of this mushroom by describing it or by telling it the species of mushroom we want, it does not do a good job. And what your work says is that if we want it to do a good job with that mushroom, we have to get a lot more training data.
It's not like we can give it one additional image. We have to give it exponentially more data. And the more data we give it, the better it will perform on kind of an exponential basis, hopefully I said that correctly.
That's correct. To increase performance on any concept that you can have in the world, you will require much more data than you probably will have at your disposal. And that's the key finding, essentially, yes.
Is this related to the concept of memorization in large language models? This has been something that's in the news recently, as I'm sure you know, The New York Times has sued OpenAI, and in the lawsuit, they pull out some specific examples of ChatGPT output that basically matches, you know, paragraphs or entire articles from The New York Times.

And too on the academic side, people have looked at tabular datasets and seen that models that have good performance on outputting certain kinds of analysis on tabular datasets have “memorized” portions of the dataset. Is this the same concept, or is this a different concept? How should we think about your finding in the context of memorizing training data?

Yeah, so the broad picture is similar for both. So in our work, we do not explicitly tackle memorization because we are not saying that this particular instance of a cat was there in the training data.
That's why if you test on that particular instance of a cat, you get better performance. Our work just says that for the broad concept of cat, if there are more cats in the pre-training data, you will get better performance. However, I think the sort of high-level connection with the memorization research that you talked about is still the same, because in this memorization research, to the best of my knowledge, what they say is that the more instances you have of a particular concept or a particular instance, the more memorization is prevalent in these models.
So, for instance, out of the The New York Times articles, if you have a particular article multiple times in the dataset, your model is more likely to repeat it verbatim. And that's the sort of high-level connection between the memorization literature and our work. Even though we don't explicitly discuss memorization, the key sort of binding piece of frequency is still the same.
I also wanted to ask about the relation between objects. So in your paper, you have an example, and you talked about this, of pulling out the nouns to identify concepts. So you have a simple sentence, “A man is wearing a hat.”
And to develop concepts, you can pull out the word “man” and the word “hat.” But I wanted to ask about the word “wearing.” And the reason I'm asking is I read a paper a while back which had a pretty interesting example.
An astronaut riding a horse versus a horse riding an astronaut, and any text-to-image model if you go and ask it to produce a picture of an astronaut riding a horse, it can do that pretty easily. I tested it this weekend. It looks fantastic. The most advanced models, and again, I tested this this weekend as well, can still not output an image of a horse riding an astronaut.
The model has the concept of a horse and an astronaut separately, presumably in its dataset, it knows these concepts, but the relation between them, I guess, is always something riding a horse, and not very often a horse riding something else.
Can a horse ride an astronaut?

I recently came across a wonderful 2023 paper by a group of researchers at SensiLab at Monash University in Australia. The paper is called “Is Writing Prompts Really Making Art?” and I encourage you to read it. In the paper the authors explore one of AI's most exciting advancements: text-to-image systems. They note the following:
You know, a human could do this pretty easily. Like, it would look silly, the picture would look silly, but a human artist could draw that picture.
Does your work say anything about the relation between concepts and how a model might fare?
Currently, in our work, we do not tackle these relations or compositions of particular objects at all. However, the implication is very clear in your example that you took of a horse riding an astronaut and an astronaut riding a horse.
If you just literally Google these, for example, you will find way more instances of an astronaut riding a horse compared to a horse riding an astronaut. Right. And this just means that the web has more images of the former than the latter.
And our implication in the work is that if you did this concept frequency at also a higher level of abstraction, where you take into account nouns and verbs, you should still see the same trends holding. We did not do this explicitly, but I'm reasonably confident that, for example, the things that you just mentioned, like with the horse and astronaut example, if you just replicated our analysis, it should hold up.
I also wanted to ask about a figure and some findings you had in your paper.
In Figure 3, you show that there is a big jump in model performance going from the concept frequency of 1,000 to 10,000.
There was a large jump in zero-shot performance. The jump was not as high for the next order of magnitude. So from 10,000 to 10,0000 or from 100,000 to a million.
So this is kind of like the log scale or the order of magnitude scale. So there seems to be something special in terms of the zero-shot performance going from a concept frequency of 1,000 to 10,000.
Is that a very common finding, or how should I think about that?
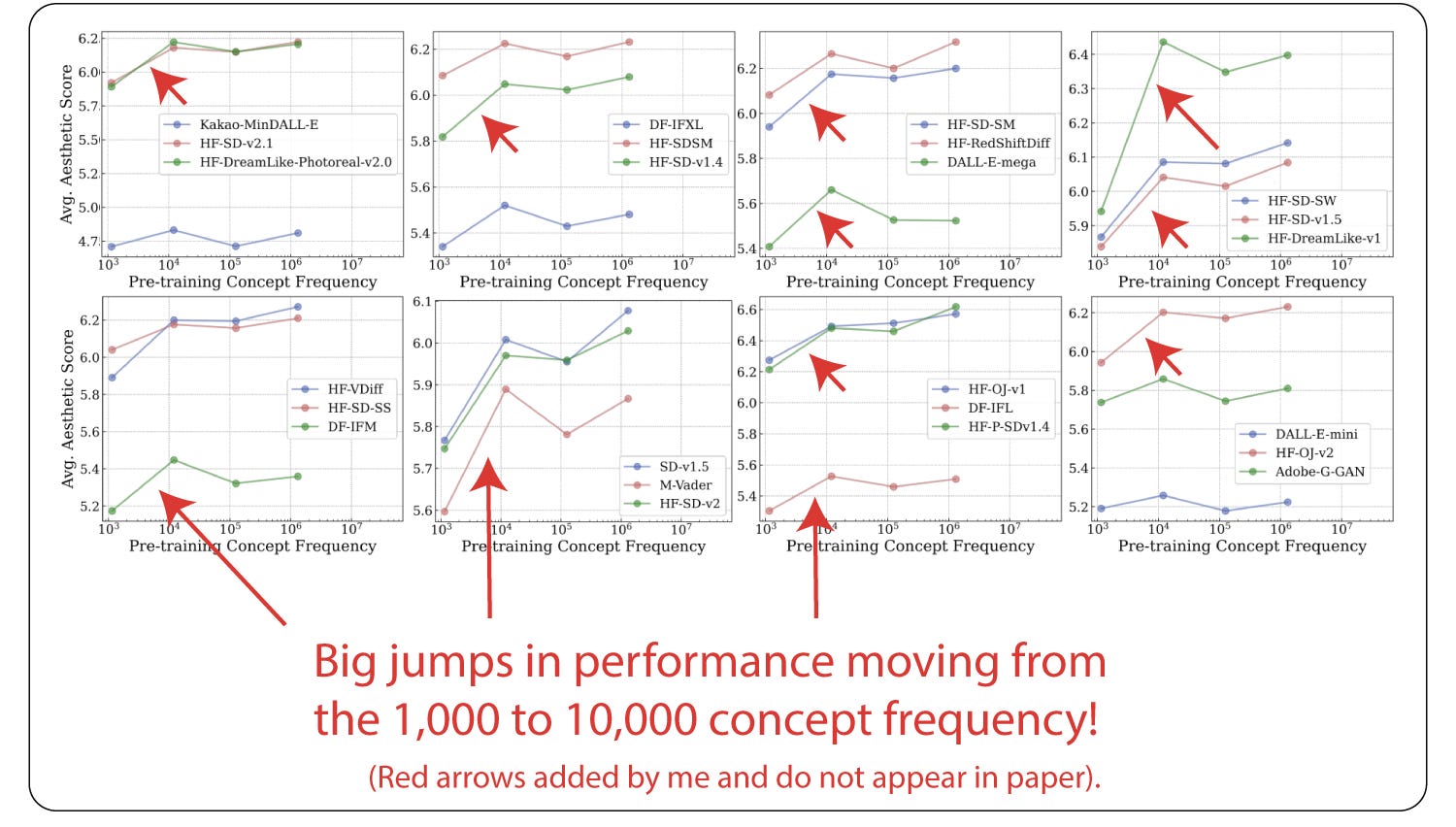
Yeah, that's a great question. Again, no, I don't think it's a common finding. In fact, we were also slightly surprised when we saw these results. And more so than thinking about this as a special case, I would sort of caution here that it's more about the exact datasets that we used in this particular experiment, where the concepts are definitely much larger scale in frequency.
However, the datasets are sort of slightly more biased here. By datasets, I mean the evaluation datasets. That's why to try to see if the same findings from the CLIP models were there for the text-to-image models, we reran an experiment with human evaluation — and this is pretty interesting — where we took the names of about 100 or 150 famous personalities, and we tried to generate images of these personalities using a text-to-image model.
And then we reran the experiment by asking humans to evaluate the quality of the generated images. And we have this particular plot in the appendix of the paper. And there again we see the same findings as before, where from 10,000 to 100,000 to a million, it still grows linearly.
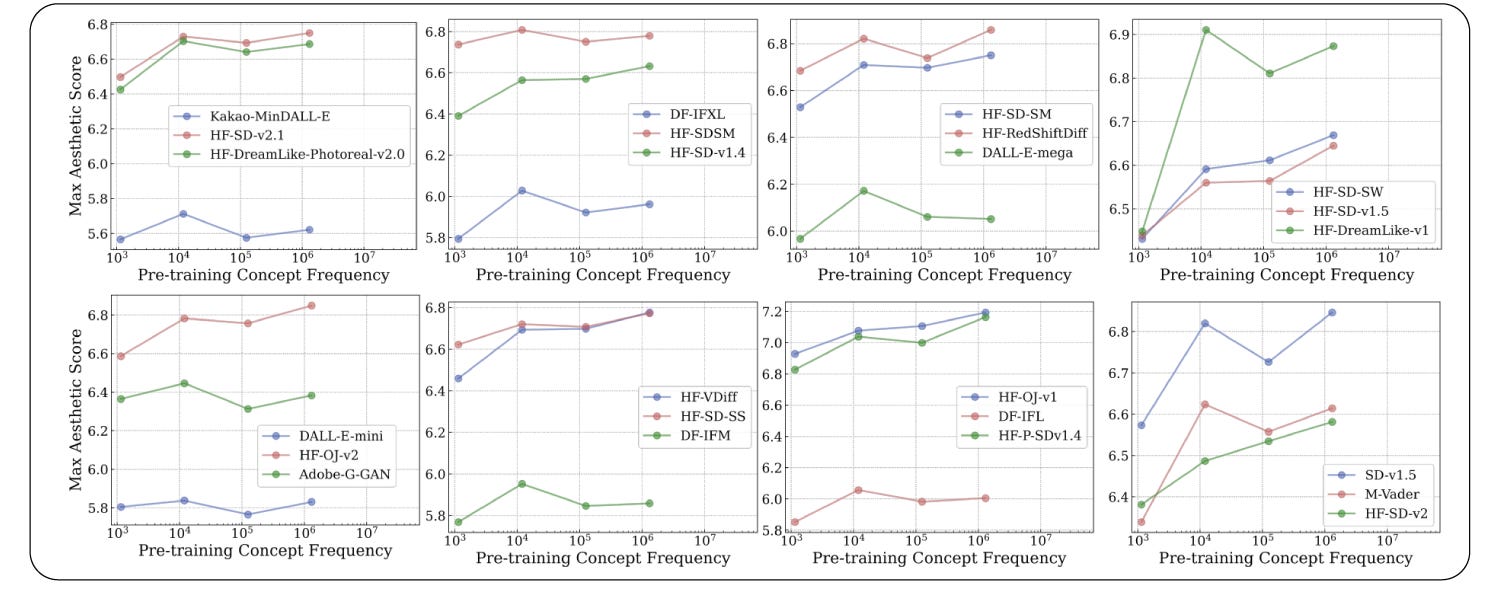
So I think the plots in Figure 3 are more an artifact of the metrics that we use and the particular datasets, rather than being a special case.
Interesting. Okay.
What should we kind of make of these findings in your paper? It's a counter, I guess, as you were mentioning, to the point that all we need is scale. And it does seem that scale helps, definitely in certain cases — like more images are better, and for the language models, more language is better — but your paper cautions that data is not infinite, and if we need to get exponentially more data to get linearly better performance, we're going to run out of data at some point, or the data is going to become very costly to get.
So what should we make of that? Maybe we can start with thinking about something like synthetic data. Is synthetic data potentially a solution to this problem?
Yes, I think synthetic data is on the rise, definitely now, of course, because there's more and more people playing around with these models. So there's more and more synthetic data samples going on to the web.
However, I would caution here that these synthetic data samples are really just a regurgitation of samples that these models were trained on. Right? So if you ask a model to produce an output of some kind, that might in some sense either be in the pre-training data, so it's already there in the real world, or it's a composition of some concepts from before. So really synthetic data, in my eyes, is not going to give you new data, so new in terms of actual real-world data, but it's going to help you try and get your model to train better, because you can have certain curriculums during your training, rather than simply randomly training on a bunch of data sets.
You can try and order these data sets from easy to hard, for example, and this will help models generalize quicker to a different sample. It's all a question about, given the data you have, how can you make better use of it, rather than how can we get more data? Because clearly that is not going to be the end on solution.
And what about something like using retrieval augmented generation (RAG)? So just for listeners, this is kind of like a database that can help augment a model when it's asked a question or needs to follow some instructions. It can go look up some information in a database to kind of remind itself of what to do or get more specific information.
So would that help at all? Like, if there's a low-frequency concept, I'm kind of doing this off the top of my head. It might be a silly idea, but if there's a low-frequency concept, could we look in some kind of a database to have the model remind the model of what that concept is to help it with performance?
Yeah, this is actually a really great question, and your intuitions are perfect.
I think this is actually one of the best ways we can currently sort of mitigate this problem, because if you think about it, low-frequency concepts in the pre-training dataset are still absolutely high in number, right? So if you think about 10,000 versus a million, 10,000 is low frequency when you look at the pre-training dataset. But 10,000 is still an absolutely high number, and you can leverage these 10,000 examples at the time when you're testing these models and playing around with them to do some sort of retrieval augmentation. And this should definitely benefit performance.
And there is a bunch of work. So we also had a paper on this some time ago where you can simply, at test time, try and do some retrieval augmentation to boost up the frequency of the concepts that you might not have seen as frequently in the pre-training data set. And this definitely improves performance.
So currently, this is actually one of the solutions that works well, but it's still sort of patching the problem and not really fixing the root cause.
And so what are some other solutions that might fix the root cause? Is it somehow better datasets or different architectures that can do a better job of making use of the data?
You have an interesting line in your paper. You say your results, “clearly reveal data hungry learning, i.e, a lack in current multimodal models’ ability to learn concepts from pre-training datasets in a sample-efficient manner.” And I guess what you've been saying throughout our discussion is that the key part of that phrase is “sample efficient manner.” So how do we make as you said, the most use of the data that we have, we've talked about a few ideas. What are some other ideas that have been researched or that you're looking at that might help that efficiency?
Yeah, good question. So, like we talked about, synthetic data is one example where you can try and not get new data, but you can try and condense more information into one particular synthetic image sample.
Right. So, for instance, you can have a very dense synthetic image that you will never find in the real world, but that one image captures a lot of real world concepts. So that would be sort of one example where you try and condense a lot of real world knowledge into one example, and this will help the model learn more from that one example.
Similarly, another thing you could do is sort of arrange your training data in such a manner that you sort of train on easy examples first, and then you gradually learn these sort of harder examples later. So in the literature, this is called curriculum learning. It's also very related to how the school educational system is organized.
So you first start by learning a bunch of initial concepts that are very easy to grasp, and then as you go further, you learn harder examples. And this sort of idea can help make the training process more sample efficient.
Because you sort of grasp the initial ideas and the initial fundamentals earlier on, and then you can try and learn to abstract them into, or compose them into higher order concepts together. So I think synthetic data is one avenue, and this sort of way to do curriculum learning on the pre-training datasets is a good idea as well.
Interesting. Yeah, curriculum learning sounds like a novel idea.
I wanted to ask you, your work seems quite important. I think it was pretty well received. I follow a lot of AI researchers on Twitter, and I think a lot were tweeting about this paper and its importance as we discussed. The idea of scale being really important for models is something that's been discussed for some time now, and your paper puts a big asterisk on that.
But scale has been studied a lot. These datasets have been studied a lot. The models have been studied a lot.
I'm curious why no one was able to come to this conclusion that you and your co-authors came to. What do you think was unique that allowed you to come up with this finding?
Yeah, it's an interesting question.
I'm not sure how to contextualize this because essentially, when we were starting this project, we didn't really think about what sorts of results we will get. For example, with the log-linear scaling or the exponential data result. We were really interested in trying to find out why these models work well in the first place.
So I think, like, taking this fundamentalist approach to research is really important because we are trying to answer a very simple questions. The things that these models can do, is that because of things they've seen previously during training, or is that because of something else? And scale really matters a lot for doing some sort of generalization outside. And I think the reason people might have sort of overlooked this, or maybe not really come to the conclusion is because a lot of people do not really look at the pre-training datasets and the downstream datasets and how they relate to each other, because it is a lot of work. You're just looking at a bunch of images and try to understand correlations.
However, a lot of work in the modeling side. So how do you design better architectures? How do you design models to be efficient? And things like that really sort of spur your intellectual curiosity. And I think that's why maybe researchers have sort of overlooked the data side of things and done more work on the model side of things. And really, I think there needs to be a reawakening where we really go back and look at the data sets that we are training our models on, because these are massive and we have to get better techniques to understand what's actually in them.
Tracing AI Data Origins

Let's say you're on the edge of developing an awesome new AI language model. But here's a critical question – how do you ensure that your use of training data aligns with its licensing terms? How do you even find out what the licensing terms of that data are? Here’s another question: how do you find out where the dataset came from and what's inside? And…
And I see a ray of hope here because there's a bunch of people really gunning at this data-centric approach to machine learning, rather than purely looking at the modeling side and assuming that the data is fixed and it's there. So I think, yeah, a data-centric lens on these things will actually be really fruitful to understand why and how our models generalize.
We're almost out of time. Is there anything else you want to mention about your work and what you found in this research? One thing we haven't touched on is that you found a mismatch between some of the text descriptions and images that those text descriptions allegedly describe. Is there anything you want to say there or any other findings we haven't touched on that would be interesting for listeners?
Yeah, it's interesting. You bring up the misalignment point, and I think it was quite interesting for us to see the pure amount of misaligned image-text pairs in there.
And if you think about it for a second, it's clear why it happens, right? Because the way these datasets are sourced, they are just scraped off of the web and you get the images and the text captions for these images are simply the alt-text tags. So on websites, when you cannot load the image, there's always an alt-text tag that is displayed, right.
And people who are uploading images onto the web can be lazy, right. Or they do not want to really describe these alt-text tags very well, for example. So it's clear why this misalignment happens, because if you simply take images and their alt-text tags, they're not always going to describe the images correctly.
So that's an interesting finding we had. And some interesting work in how to fix this, is you simply try and change the captions to match the images better, for example.
So I think our work overall, because we took the data-centric lens and the data-centric approach to finding things, we hope that we create an ecosystem where people will go back and look into the datasets and use our sort of data artifacts to get a better understanding of datasets. So misalignment was one thing we analyzed, but there's so many more things you can analyze as to how the datasets look like.
Yeah, I think the misalignment results from web developers not having a focus on accessibility for a large portion of the web's existence, because these alt tags are usually used for people who use assistive technologies, maybe screen readers, and they need things described for them on the webpage because maybe they're visually impaired.
That wasn't a big focus for web developers for a long time. So like you said, there's oftentimes really bad descriptions because it's just humans who are, who are writing these, as you mentioned, you're just uploading a picture. A human is describing it.
They can describe it in any way they want. Sometimes they would leave text descriptions off altogether. So, as you said, I guess it's not, it's not surprising that we've kind of ended up in the, the place we are today.
Let's, let's close by talking about what you're doing next. Do you have any exciting research projects? Are you continuing this line of research? What are you up to?
Yeah, so we were super excited about the reception to this work. And sort of looking at how people were trying to follow up on this and create more projects. So I particularly am focusing on extending this work in trying to understand what are better data curation methods, what are data filtering methods that would work well, and also how do we actually want to implement these curriculum learning methods, for example, that will help us make more sample efficient learning algorithms.
So I'm broadly extending this work where we showcase the problem. And my future work is sort of going to be to try to solve these problems and give us better algorithms or better data filtering mechanisms.
Vishaal Udandarao, thanks for being on the podcast.
Yeah, thank you so much.