

Translating endangered languages with off-the-shelf large language models
A conversation with Kexun Zhang on LingoLLM

There are currently 7,000 languages actively spoken in the world and about 40% are endangered, at risk of disappearing forever (see map below, click for a larger version). Can Generative AI systems help us with preservation and education about these languages via translation into English or other high-resource languages? Not today.

Current state-of-the-art, off-the-shelf large language models like OpenAI’s GPT-4, Anthropic’s Claude Opus, or Google’s Gemini are able to translate easily between high-resource languages, say translating Spanish to English. But training data for low-resource and endangered languages is sparse and absent from the pre-training data sets used by language models, like the Common Crawl, discussed in last week’s episode.

But a team of researchers at Carnegie Mellon University and UC Santa Barbara is trying to solve this problem. They’ve developed LingoLLM, a workflow and pipeline for improving the translation capabilities of large language models for low-resource and endangered languages that don't have much digitized content. Importantly, the workflow doesn’t require any additional training of the language model or special fine-tuning.
This week I spoke to Kexun Zhang, a PhD student in computer science at Carnegie Mellon University, who helped lead the first phase of LingoLLM’s development.
The LingoLLM workflow automates the creation of a package of linguistic artifacts — like grammar books and a gloss — both of which we talk about during our conversation. This package can then be passed to off-the-shelf language models as part of a structured prompt along with the passage in the low-resource language that needs to be translated. LingoLLM upgrades off the shelf language models from essentially useless in translating low-resource languages to a translation tool that, while not perfect, is still pretty good.
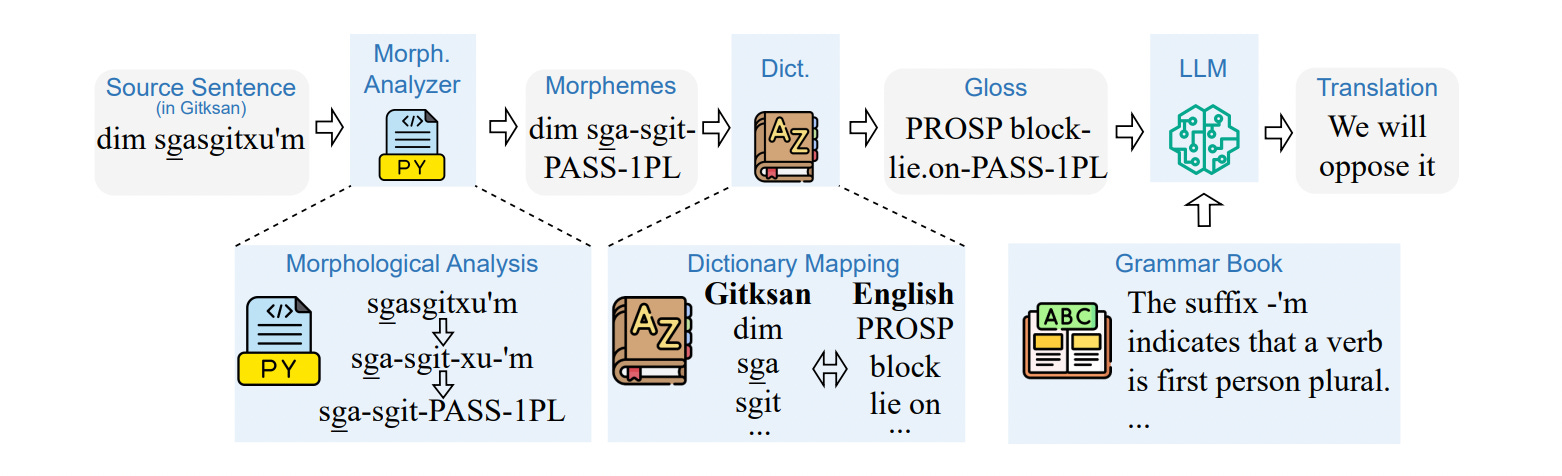
Here’s a diagram from the LingoLLM research paper, outlining what the process looks like. Kexun and I deep dive into this process throughout our conversation.
To evaluate LingoLLM the workflow was compared against the translations of human experts that are known to be correct. The table below from the paper gives a really tangible sense of how much better LingoLLM is than off-the-shelf language models.
Looking at the first column, “Input” is the original sentence in the native language. The “Ground Truth” is the translation from a human translator, known to be correct. “LingoLLM” is the translation result using the method Kexun and his coauthors developed. “Few-shot” is the result of an off-the-shelf language model being given a few pairs of parallel sentences and then being asked to translate a new sentence in the Input language into English. In this case two off-the-shelf language models were used: GPT-4 and Mixtral-8x7B. The poor translation capabilities of off-the-shelf language models is a result of the model not having enough data in its training set for these low-resource languages.

Kexun and I talked about how he got interested in linguistics, provide some background about low-resource and endangered languages, and talk in detail about the workflow behind LingoLLM and what challenges remain. I had a great time talking to Kexun, and I think you'll enjoy the conversation.
This transcript has been lightly edited for clarity.
Kexun Zhang, welcome to the podcast.
Yeah, excited to be here.
To start out with, I wanted to talk a little bit about your interest in linguistics. You have a note in your article, “Several authors of this paper are either speakers or children of speakers of endangered or low-resource languages.” And I wanted to ask, is that the case with you? Are you one of the authors that is in that boat?
Yeah, I am.
I'm a native speaker of Wu, which is a Chinese dialect that was different from Mandarin. And it's kind of a low resource language because although a lot of people speak it, you can't really find a lot of resources of this language online, partly because it's mostly spoken instead of written. And my parents and my grandparents also speak this language. And in fact, my grandparents only speak this language. So that's the language I talk to my grandparents in.

And did that background growing up speaking a low resource language, is that kind of what spurred your interest in linguistics and this line of research you're undertaking?
Yeah, I think that's part of the reason. Because when you grow up speaking two languages, you can't help but notice the differences and the nuance of different languages and their pronunciation, their vocabulary. And that kind of gets you interested in linguistics. So that's part of the reason.
Before we talk about the specifics of your article, I wanted to go over a few foundational items. I wanted to start with a couple of different terms you use for the kind of languages you're using AI to help translate. One of those terms is “low-resource languages” and the other is “endangered languages.” Are there differences between those two terms and categories of languages, and if so, help walk us through what those differences are?
Yeah, I think there are very major differences.
So an endangered language, of course, is usually low resource. But a low-resource language doesn't necessarily have to be endangered because, for example, Wu is not really endangered because a lot of people speak it, but it's low resource because you can't really find a lot of data in that language.
“Low resource” is mostly referencing the availability of digitalized data of a language, but “endangered” is mainly referencing how many people are still using it and whether the next generation, our children, will still be speaking that language.
So when we think about the specific artifacts that are lacking for low-resource languages, does that mean it's referring to things like dictionaries and grammar books in that language?
Yeah, I think it's mostly about books and audio speeches, recorded speeches in that language. But I think dictionaries and grammar books have a much higher coverage for a lot of languages.
And if we think about endangered languages, what does that translate to in terms of the actual number of people speaking that language?
Yeah, that depends on the level of endangeredness. So there's this UNESCO report on in endangered languages, and they sort of rank the languages according to how endangered they are. The most endangered languages are called nearly extinct languages.
So for some of these languages, number of speakers is really small, like for Manchu language we did in this paper, there are, I think, only hundreds of speakers still alive. Native speakers.

And these efforts to preserve endangered languages, they must predate AI, right?
Yeah. Yeah. There are definitely already lots of efforts going on to preserve these languages before AI. I mean, even before computers, because field linguists tend to, you know, document these languages for a lot of different purposes.
And also when people grow up, when people tend to care about their mother language, you know, even if they're not linguists and they want to preserve it. For example, there is this project in China that creates recordings and videos of lots of common phrases in a lot of different Chinese dialects. So there is a lot of effort trying to preserve languages.
In preparation for our conversation, I did a little experiment where I found a random passage online in English. I went to ChatGPT and asked it to translate that passage into Spanish. It did so. I went and I checked the accuracy of that passage by taking it to Google Translate and having it convert it from the Spanish output of ChatGPT back into English and compared it with the original. It was quite accurate, almost exactly the same.
So it seems that large language models are able to have some kind of translation capabilities, at least for popular languages like English, Spanish, I don't know, maybe German, maybe some other languages, even though they're not explicitly trained to do translation, it just seems to happen by magic. So how is that possible? Talk a little bit about that.


Yeah, that's a great question. So large language models are pre-trained with the next word prediction objective, which basically means giving the language model a prefix of a passage or a sentence and asking it to predict the next word.
So it seems that it's not really doing any translation. But according to some previous studies, there is some incidental bilingualism in their training data. So there's this paper from Google where they study, what does the training data of a language model look like? And they found that there are actually a lot of parallel sentence pairs in the training data of a language model.
For example, if you look at a website that is actually a textbook for English speakers learning Spanish, then there will certainly be a lot of English-to-Spanish parallel sentence pairs. That's probably one of the reasons why it's also able to, you know, translate without actually being trained to do so explicitly.
And also, when the language model is learning a language or multiple languages, people found that the common words, the words in different languages that refer to the same entity, tend to be sort of aligned in the representation space. So that's also probably one of the reasons why language models can translate.
And do we know how much data it takes for a large language model to be able to learn to translate between languages?
According to some experiments by Google Translate, about 100,000 pairs of parallel senses can get you reasonable performance, but it kind of depends on what language you're talking about. And, yeah, there's a lot of confounders.
I think the last thing to touch on before we dive into the specifics of your translation workflow are a couple of the artifacts that are central to your process. One is a dictionary, and the second is a grammar book. I assume people know what a dictionary is, but maybe it's worth quickly going over those two artifacts and telling us what we need to know there.
Yeah, a dictionary is basically a mapping from words in a language to their definitions. And the definitions can be written in a different language. Of course, they can also be written in the same language, which is the case for a lot of English dictionaries. In our case, this dictionary is basically mapping the words of English to some endangered language, or mapping the words of an endangered language to their English definitions.
And a grammar book basically talks about the grammar of a language. And, you know, the grammar here actually covers more ideas than, you know, when we talk about grammatical errors in an article, because the grammar here usually includes:
The phonology of a language, like what sounds are in this language and how are they composed to create words.
Morphology, which is basically how smaller units of meaning are put together to construct words, which is a larger unit of meaning.
Syntax, which is how words come together to form sentences.
Semantics is how we compute the meaning of a sentence.
All these different layers of a language are included in the grammar book.
All right. Anything else we should touch on before we dive into the specifics of the translation workflow?
Well, I say there are two things. The first is that while this paper has proven it's useful for some languages, a lot of endangered languages are not really in written forms. They're actually mostly spoken, so there's no way this paper can help them. So that's a huge limitation. We should keep in mind that the raw form of a language is speech instead of text.
And the other thing to keep in mind is that we choose to use dictionaries and grammar books for inanimate languages, mainly because it's really hard to get a large corpus to train language models or train translation models for them. Because in some sense, if you do have a large corpus, a model that is trained to do translation is always going to be better than this sort of symbolic method.
So you and the team applied your workflow to a total of eight languages:
Manchu (mnc)
Gitksan (git) [also spelled Gitxsan]
Natugu (ntu)
Arapaho (arp)
Uspanteko (usp)
Tsez (ddo)
Bribri (bzd)
Wolof (wol)
How did you decide to choose these specific eight languages?
It's basically dependent on how easy it is for us to find a good dictionary. By good dictionary, I mean a dictionary that is digitalized and that is, you know, easily operable using a program. Because for some languages, their dictionaries are actually typewritten. So it's really hard for us to, you know, first we need to scan them and digitize them, and then, you know, write a script to parse them, and that's kind of hard. But for some of these languages, it's rather easy for us to have access to a dictionary that, you know, we can easily use.
Another reason is, since we want to do more than translation for some languages, we kind of need to ask some native speakers to annotate data for us. So that's the major reason why we chose Manchu, because I knew someone who is a native speaker of Manchu.
And how was it that you were able to find digitized artifacts for these specific languages? Because it sounds like for many low resource or definitely endangered languages, there might not necessarily be digitized artifacts available for you to use.
I think the reasons why they have digitized data is diverse. So for Manchu, it's because it's the language spoken by Qing dynasty, which is the last empire that ruled China, because they had a lot of government issued dictionaries and government documents, so people were interested in studying it, so they created the data.
But for some languages, like Gitksan, I think it's because it's a Canadian indigenous language, and I think the Canadian government and some Canadian universities really wanted to preserve this language. Yeah, they have this lab called Gitksan lab at the University of British Columbia, and their entire research focus is on this language. So they have this great dictionary for the language.
By the way, before I forget, I wanted to ask, were you able to learn a bit of these languages as you undertook this project, or even how to pronounce some of the words? Because you have in your paper a few example sentences in some of these different low resource and endangered languages, and I have to say they look super difficult to speak. Like, I wouldn't even begin to know how to pronounce these languages.

[Laughs]. Yeah. It's also very unintuitive to me, too. And I kind of learned how to pronounce Manchu words, and I learned some, like, simple phrases, but I didn't really learn any of these languages to a reasonable level.
All right, so let's go over the translation workflow. There are a couple of steps involved in preparing the material that is then passed over to the large language model so it has enough understanding of the language to effectively translate it into English. And the first step involves something called a morphological analyzer.

So tell us what that is and more about the first step in this workflow.
Yeah, yeah. So the first step in our process is called morphological analysis. So what it means is basically splitting words in an endangered language to smaller units, smaller meaningful units. So these units are called morphemes in morphology. And what they mean is they're just, you know, the smallest meaningful units in a language.
So in English there are morphemes, too. For example, “cats” can be split into “cat” plus a plural marker, ‘s.’ So these are two morphemes in the same word, and an English morphological analyzer would split them into “cat” plus plural marker.
And the reason why we want to do this are twofold. Firstly, for many dictionaries, they only have the definitions for the stems of words. Like some English, dictionaries don't have the definition for “cats,” but they do have the definition for “cat.”
So one reason why we're doing it is because we want to make it easier for us to look up the words in the dictionary. That's one reason. The other reason is that some morphological analyzers can sort of give you the grammatical functions or grammatical features of these morphemes.
For example, if you have an English morphological analyzer can tell you that ‘s’ here is a plural marker, and this type of grammatical information is important for the following steps.
And I know there were some linguists involved in your project. Did they create any of these morphological analyzers specifically for this translation project?
Well, we did work with linguists. We did found some languages where morphological analyzers didn't exist, but we didn't really create any new morphological analyzers. However, the computational linguist we worked with told us that for an experienced linguist with access to the grammar book, it shouldn't be very hard to create a morphological analyzer using that book. So that's why when we talk about the coverage of these linguistic resources, we talk about their coverage of grammar books, not morphological analyzers, because a grammar book is sort of a more descriptive document for the language, and it can be converted to a morphological analyzer without a lot of trouble.
Okay, let's talk about the next step in the process. So, just to quickly summarize where we're at right now we have a passage, we want to translate that from some low-resource language into English.
We break the passage into words, and then we break the words into these morphemes you're mentioning. I think that makes a lot of sense. Once we have these morphemes, which is like a stem and some additional conceptual elements, like you were mentioning plural markers or other things, what do we do with those morphemes?
Yeah, we take these morphemes like the stems and the other morphemes, and we map them to their definitions in a dictionary. So this is a rather intuitive step because this is what you do when you learn a new language. You look up these words in the dictionary. So usually in your mind, when you are looking up words in the dictionary, you sort of do the morphological analysis yourself. Right. You don't look for the words in their exact original forms. You look for their stems. But in our case, we do it sort of using a script to do that, and then we look for them in a dictionary.
But the dictionary itself can actually be messy because, firstly, for many languages, they have different script systems. You have different ways to write them. And we want to make sure that the way they're written in our data, in our morphological analyzer, is the same as the way they're written in the dictionary. So that a word that is spelled differently shouldn't be hard to find. That's a messy step.
And another interesting thing is that some dictionaries have, you know, these links to related words. Like, for example, if a word is derived from a stem or another word, sometimes a dictionary doesn't really contain the meaning of the derived word in its definition, but it will point you to another entry of the original form or the stem. And then you need to, you know, go across that link to retrieve that entry and combine everything and give it to the model.
You said something interesting there. You mentioned that the words might be spelled differently in different script systems. But what did you mean there? Is this like how the word color is spelled differently in British and American English (colour vs. color), or is it something different?
Yeah, it's kind of similar because, like, the words that are pronounced the same are spelled differently. But in our case, it's that, well, take a single sound in Manchu — “sh” — is written as an ‘x’ in one script, but as an ‘s’ in another script. So this is the situation we were encountered.
I see. And what is the history or the reason behind these different script systems?
These scripts are created by people who documented the language. In Manchu's case, it was created by some missionaries, I think, or some ambassadors to China, because different people created these scripts. They had different writings. Yeah, that's basically the case.
And I think the next step involves something called a gloss. Do you want to talk about the next step and what a gloss is?
So you have this original sentence in some language, right, in say, Manchu.
And a gloss of the sentence means you take every word in the sentence, split it up into morphemes. Then you, you know, you map the stems to their English translations, and you write everything down in the same order as the original sentence. That's basically something a human translator would do if you're translating a sentence, you would look up things in a dictionary, and you would write the corresponding English translations just below that exact word. And this process is called glossing.
The difference between directly writing the word and writing all the other stuff is kind of important because you need to have the other stuff, like plural markers and tenses of a verb, voice of a verb to better translate the sentence.
All right, I'm going to summarize again quickly where we are. So we want to translate a low-resource language into English. We break up the low-resource language into words. We take each word and get its morpheme. We can use the stem of the morpheme to look up the word in a dictionary. We can repeat that process for every word in the passage. So we have a gloss, which is a mapping from every word in the original low-resource language to the corresponding meaning in English. And then what do we do next? What do we do with that gloss?
Yeah, so with that, we have the gloss, and then we feed the gloss and a grammar book to the language model. So the grammar book is basically the entire grammar book of that language, or in some cases, the summary of the grammar of that language.
And so you're able to provide the original passage in the low-resource language, the gloss and the grammar book to the language model. And using this kind of package of artifacts enables the language model to use its language capabilities from its training to be able to take that data in that package and translate the low-resource language into English. And the great thing about this workflow is you can use it with off-the-shelf language models. It doesn't require any special training, which I think is really cool.
I want to talk about the evaluation you do, and you kind of have some tables in the book showing how much better your method is than just using a standard language model without passing in these artifacts. Because obviously the language model doesn't have these low-resource languages in its training set, so it really struggles.
Just to give one concrete example for listeners, you compare the translation of a sentence in I'll do my best to pronounce this language, Arapaho, into English. And Arapaho is a language that's native to the people of Wyoming and the neighboring states. And you're able to evaluate the large language model's performance on this translation activity because you have some high quality translations by humans, which are known to be correct.
And so you can compare those high quality translations to what the language models produce and see how close they are. So for this sentence in Arapaho that's translated into English, the actual english translation is the sentence “He inadvertently walked in where people were sitting,” and your workflow produces a sentence which is pretty similar, “Someone accidentally entered this room where people sit.” So I'll quickly compare those two again.
Ground truth: “He inadvertently walked in where people were sitting.”
Your workflow: “Someone accidentally entered this room where people sit.”
Again, pretty good, maybe not perfect, but quite good.
If we compare that to the base large language model, it just produces nonsense. Its translation is, “I'm going to work for you tomorrow,” which of course, has nothing at all to do with the original sentence. So your method is quite an improvement over the base large language model’s capabilities for translating these low-resource languages. And we can talk in a moment about the challenges and some areas for improvement. But why don't you go over the specifics of how you did this evaluation. There was a quantitative measure scoring metric that you used, and talk about some of the results there.
So in the evaluation, the metric we used was called spBLEU (BLEU stands for Bilingual Evaluation Understudy). So what it means is when you compare two sentences, the your translation and the actual ground truth translation, they have this tokenizer that would break up each translation into sub-words, like maybe some of them are entire words, some of them are sub-words, and then they would compare the overlap of n-grams between your translation and the ground truth translation. N-grams basically means a consecutive list of words. So a bigram is two consecutive tokens, and a fourgram is four consecutive tokens.
And then, you know, if your fourgram matches with a fourgram in the ground truth translation, that would mean you're doing something good, because, you know, if it's not good, then they shouldn't really have a lot of overlapping tokens. That is basically the evaluation score.
And for the baselines, like the methods we compare to a zero-shot basically means you just give the input sentence to the model and ask you to translate it to some language. And zero-shot chain-of-thought means you ask to translate to some language step-by-step. And few-shot basically means you give several translation examples to the model and ask it to do a similar thing. So, for example, if it's the case for Arapaho, you would give three English Arapaho translation pairs to the model and then give the fourth input, which is your actual input to the model, and ask it to translate that to Arapaho.
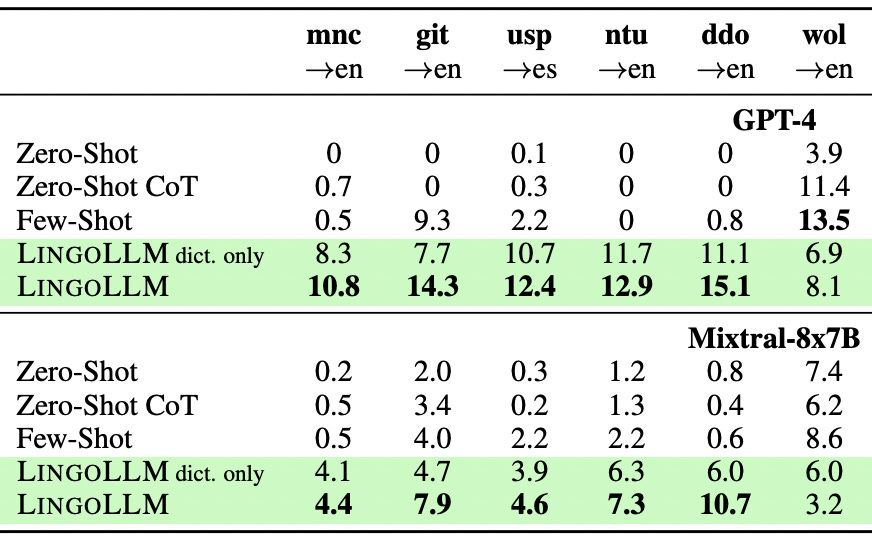
And how does your method compare to other state of the art methods or other AI language specific technologies? So maybe, I don't know, is Google Translate, does that have any of the languages that you tested on so that you could compare against that as kind of another evaluation metric?
Yeah, if you look at Google Translate and their list of languages, you would find that I think most of our languages are not supported by Google Translate. I'm not sure if all of them are not supported. At least Manchu, Gitksan, and Arapaho are not supported by Google translate. And the reason why they can't really do it is partly because there's just not enough data for that language.
And what about a large language model trained specifically for translation in one of these languages? Are you aware of any research in that area?
Yeah, I think so. There is one language, the code for the language is wol, and it's called Wolof, and it's included in Meta's “No language left behind” paper.
So they did train a model for that language, and our performance is not as good as the performance they showed in their paper. So I think that's why when the resource for a language is large enough, we should at least consider training a specialized model, or maybe a hybrid system that utilizes both a learned model and the linguistic resources.
So let me see if I can summarize the approach. If we think about it as a simple decision tree we mentioned earlier, we have this 100,000 parallel sentence threshold, roughly 100,000 parallel sentences. And above that level, we can train an AI or a large language model to translate between two languages, and it will have reasonably good translation performance.
So if we have that much data and we're really focused on translation, and we're ignoring resource constraints and that kind of stuff, then what we should do is train a dedicated model because we have enough data and we're going to get quite good performance if we can train a model using all of that translation data that we have.
If, on the other hand, we have near zero parallel sentences, we could use the workflow that you and your co authors develop that we've been talking about in this conversation.
And if we happen to have somewhere in the middle, like, say, we don't have 100,000 parallel sentences, but maybe we have 60,000, we could train a model with those 60,000. It won't be great, but it will be better than a base model. And then we can supplement that with the approach that you and your co authors developed with these additional linguistic artifacts. And those two approaches together will create kind of a hybrid model or a hybrid workflow that will be quite good at translation.
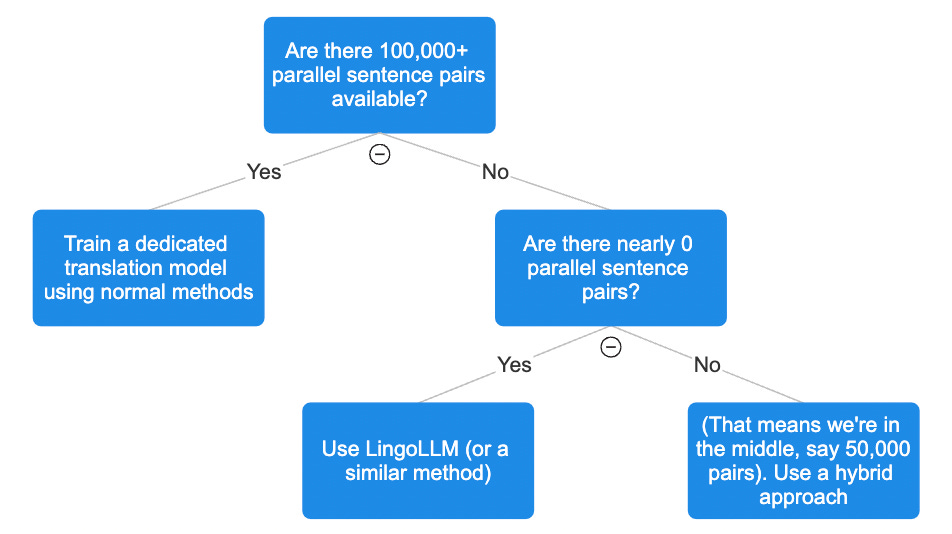
Is that the idea?
Yeah. Yeah, I think that's the spirit. But the threshold might, I guess, change as the technologies get more advanced. But that's the spirit.
And say why you think the threshold might change in the future? Just better language models?
Yeah, because I think people are still like the training. A better model with fewer data is still like a very interesting area to a lot of researchers. So I imagine the threshold might get lower.
So what are your hopes for the next steps for this project? Are you hoping to extend it in some way or maybe deploy it into a production setting where the general public can use it?
Yeah, I mean, if it could get deployed, that would certainly be great, but I think the challenge here is not the system itself, but— well, first you need a good dictionary, which is not always available. Like, even if dictionaries exist, they are not really in ready form to be directly plugged into our system. And also, if we want to put a huge grammar book in our prompt, that's going to be very extensive.
Considering the amount of time and computation needed to process an entire grammar book, I think it's going to be more expensive than, say, regular Google translate API calls. That's, I think, another challenge. Yeah, so that's the challenges I see, if we want to actually deploy it.
But on the academic side of things, I think there's still some next steps. For example, we did a human baseline. We asked one of our authors, who have no access to Manchu before, to do exactly the same as the models do, but with a human subject, and she did much better than our method.
So apparently there is still huge room of improvement. And I think the human baseline is, like, 20 BLEU scores compared to our method, that scores 10. So that's a huge improvement. And 20 is definitely a reasonable translation quality that, you know, 10 is okay, but 10 is far from good. But I think 20 is, like a very good performance for this language. So I think on the research side of things, the idea of taking a grammar book and applying the rules in the book, this specific task is not really well solved by the existing models.
One reason could be their long context understanding ability is not that good. Also, maybe the grammar book is not properly formatted. Maybe we should use some sort of retrieval system to grab the relevant chapters and sections in the grammar book to give it to the model instead of just shoveling the entire book into it, which is going to be so much harder.
So I think, as a task, this task of translating based on the grammar book is still far from solved. So I think there are still some space for us to explore there.
And can you explain the difference in BLEU scores a little more? You mentioned that your method had a blue score of 10 compared to the human translator that scored 20. But what does that actually mean in practice, in terms of quality of translation?
Yeah, I'd say for some high-resource languages, say, English to German, a BLEU score of 30+ is kind of usual, and it's kind of the standard right now.
But the scale of BLEU is actually language dependent, like, for different language directions, the scale of BLEU kind of changes. So we can't say for sure how good 10 means. But I did manually check the translations. There are still some translations that, you know, are totally off. But when I check the human translation that has a BLEU of 20, almost all translations reflect the ground truth pretty well. So I'd say for Manchu, at least for this direction, the human baseline is already pretty good.
And another translation activity we haven't touched on yet is that you used your method to translate some math word problems, which I thought was interesting, is that just because math offers some conceptual language challenges that we don't encounter in our day to day language?
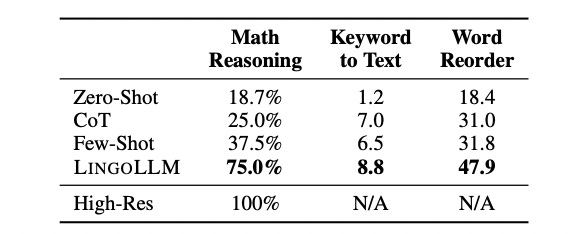
So, for the math problems, they were taken from a famous math problem set that is widely used to evaluate language models, but it's written in English. And then we ask this Manchu speaker we know to translate them into Manchu.
And, of course, there are some problems in the translation. For example, some concepts that are talked about in the problem do not exist in Manchu communities. So we ask them to use a similar concept that they know to do that.
So we did these translations for these problems, and then using our method, what we did is we translate the problems back to English. And using the translated English problems to query the model. So that means your translation needs to be good enough for the model to understand the problem. Otherwise, if it understands the problem incorrectly, it won't be able to solve it.
These problems are fairly easy. So it's not like college level, it's basically just a secondary school level. The focus here is not how hard they are in terms of mathematics, but how accurate our model can, you know, preserve the problem meaning when translated between English and Manchu.
I think for math problems, you kind of need to be a bit more accurate in translation for it to work, because natural language can be ambiguous, it can be vague, right. A lot of translations that mean literally similar things can look differently.
But for a math problem, if some part of your translation is inaccurate, it will result in a wrong understanding of the original problem, which will result in the wrong answer. So I think that's, like, one of the reasons why we wanted to use math as this special benchmark for translation. And also, yes, there are some concepts in math that are not really reflected in our normal translation benchmark, because the normal translation benchmark is just daily dialogues that hardly involve math.
Throughout our conversation, we've touched on a few challenges with this kind of language project. Some languages are spoken, not written. Some languages don't have digitized artifacts. Are there any other challenges you think are worth mentioning?
Yeah, I think another huge problem is that not all languages have an alphabet that is similar enough to, say, the English alphabet, because the languages we chose have this Latin written script. But that's not true for most of the languages in the world. Right? So to actually make this work for some language, we might need even to actually create a system of writing that is familiar enough to the language model or easy enough for the language model to process before we can actually apply our pipeline. So that's like step zero for a lot of languages.
And what exactly is the challenge there? Is it about being able to represent the language on a keyboard so it can be typed into the prompt, or, like, having the ability to represent it digitally, given the glyphs we have available?
Well, you can always find ways to represent these languages, because in the end, you can always write down their phonetic forms. You can use the International Phonetic Alphabet to write them down. But the issue is that the whole NLP pipeline, like the tokenization, for example, the part where the model splits up words into smaller chunks, are not optimized for these languages. So for lists, for characters that are very different from, say, Latin Alphabets, their representation is less well learned than the representations for, like, say, the Latin Alphabet.
Also, the same sentence in different languages might cost you different amounts of tokens. And for some low-resource language or some writing systems that are less significant in the training set, you might have more tokens for a single sentence but have a lower performance. I think that's a issue that's been studied before by other people. So they're saying, you know, for the language users, for the users of these languages, you pay more to OpenAI, but for worse performance.
We're almost out of time. I wanted to close by asking — and I don't know if any listeners will actually take me up on this — but if someone wanted to help out with the project, what's a good place to start just digitizing some of the existing linguistic artifacts we mentioned for low-resource languages or what should they do?
Yeah, I think that's a good start, to actually start scanning these books and digitize them. That's a great start. And also, I think a lot more efforts need to be put to document these in endangered languages. Like, you know, talk to the native speakers of these languages to know what they actually need, know what they actually want. Like, record their stories, their sagas, their, you know, the conversations they have with each other.
I think, you know, there are so many languages in the world, and many of them are not going to be spoken in, say, 10 years, 20 years. I'm kind of certain that a lot of them are still gonna die no matter what we do. But, you know, we should all try to do what we can to document them and try to preserve them in one form or another to at least keep in mind that we still have these languages and their corresponding cultures, their stories, their histories, you know? Yeah, there are so many things to do.
Kexun Zhang, thanks for being on the podcast.
Yeah, thank you so much for having me.